
“Finite Field Arithmetic.” Chapter 6: “Geological” RSA.
This article is part of a series of hands-on tutorials introducing FFA, or the Finite Field Arithmetic library. FFA differs from the typical "Open Sores" abomination, in that -- rather than trusting the author blindly with their lives -- prospective users are expected to read and fully understand every single line. In exactly the same manner that you would understand and pack your own parachute. The reader will assemble and test a working FFA with his own hands, and at the same time grasp the purpose of each moving part therein.
- Chapter 1: Genesis.
- Chapter 2: Logical and Bitwise Operations.
- Chapter 3: Shifts.
- Chapter 4: Interlude: FFACalc.
- Chapter 5: "Egyptological" Multiplication and Division.
- Chapter 6: "Geological" RSA.
You will need:
- All of the materials from Chapters 1 - 5.
ffa_ch6_simplest_rsa.vpatch(see here)ffa_ch6_simplest_rsa.vpatch.asciilifeform.sig- ffa_ch6_simplest_rsa.kv.vpatch
- ffa_ch6_simplest_rsa.kv.vpatch.asciilifeform.sig
Add the above vpatch and seal to your V-set, and press to ffa_ch6_simplest_rsa.kv.vpatch.
You should end up with the same directory structure as previously.
Now compile ffacalc:
cd ffacalc gprbuild |
But do not run it quite yet.
The "mail bag" from Chapter 5... is empty. Congratulations, however, to the successful solvers of the Chapter 4 puzzle!
Now, errata! In the FFACalc extensions of Chapter 5, we have:
ffa_calc.adb:
-- Multiply, give bottom and top halves when '*' => Want(2); MustNotZero(Stack(SP)); -- Ch5: slow and simple 'Egyptological' method: FZ_Mul_Egyptian(X => Stack(SP - 1), Y => Stack(SP), XY_Lo => Stack(SP - 1), XY_Hi => Stack(SP)); |
After removal of the obvious bug, this becomes:
ffa_calc.adb:
-- Multiply, give bottom and top halves when '*' => Want(2); -- Ch5: slow and simple 'Egyptological' method: FZ_Mul_Egyptian(X => Stack(SP - 1), Y => Stack(SP), XY_Lo => Stack(SP - 1), XY_Hi => Stack(SP)); |
In this Chapter, we will add a modular multiplication routine to FFA. This in turn will immediately let us write a modular exponentiation routine, which is the fundamental operation of the RSA system of asymmetric cryptography.
Concretely:
FZ_ModEx.ads:
with FZ_Type; use FZ_Type; package FZ_ModEx is pragma Pure; -- Modular Multiply: Product := X*Y mod Modulus procedure FZ_Mod_Mul(X : in FZ; Y : in FZ; Modulus : in FZ; Product : out FZ); pragma Precondition(X'Length = Y'Length and Modulus'Length = X'Length and Product'Length = Modulus'Length); -- Modular Exponent: Result := Base^Exponent mod Modulus procedure FZ_Mod_Exp(Base : in FZ; Exponent : in FZ; Modulus : in FZ; Result : out FZ); pragma Precondition(Base'Length = Exponent'Length and Base'Length = Result'Length and Base'Length = Modulus'Length); end FZ_ModEx; |
Because of the extremely simplistic and wholly-unoptimized way in which we implemented Multiplication and Division in Chapter 5, this will be a "geological-time" RSAtron, rather than a battlefield-ready one (though I can conceive of a few speed-insensitive applications where even an algorithm such as this one could suffice.) And at the end of this Chapter, we will answer the question of "exactly how geological" ?
The bulk of the material in the remaining Chapters in this series will concern itself with demonstrably-correct and safe (i.e. constant-spacetimeness-preserving) methods for speeding up Multiplication and Division -- and consequently Modular Exponentiation -- so as to transform this "geological" RSA into a generally-applicable one.
And so, without further delay, let's define the new modular multiplication and modular exponentiation operators in the FFACalc system:
ffa_calc.adb:
-- Modular Multiplication when 'M' => Want(3); MustNotZero(Stack(SP)); FZ_Mod_Mul(X => Stack(SP - 2), Y => Stack(SP - 1), Modulus => Stack(SP), Product => Stack(SP - 2)); Drop; Drop; -- Modular Exponentiation when 'X' => Want(3); MustNotZero(Stack(SP)); FZ_Mod_Exp(Base => Stack(SP - 2), Exponent => Stack(SP - 1), Modulus => Stack(SP), Result => Stack(SP - 2)); Drop; Drop; |
And now let's implement the new unit, FZ_ModEx:
FZ_ModEx.adb:
with FZ_Basic; use FZ_Basic; with FZ_Pred; use FZ_Pred; with FZ_Shift; use FZ_Shift; with FZ_Mul; use FZ_Mul; with FZ_Divis; use FZ_Divis; package body FZ_ModEx is |
We will begin with the modular multiplication algorithm. It is deliberately made in the most straightforward way I could think of, making use only of "schoolboy" methods:
-- Modular Multiply: Product := X*Y mod Modulus procedure FZ_Mod_Mul(X : in FZ; Y : in FZ; Modulus : in FZ; Product : out FZ) is -- The wordness of all three operands is equal: L : constant Indices := X'Length; -- Double-width register for multiplication and modulus operations XY : FZ(1 .. L * 2); -- To refer to the lower and upper halves of the working register: XY_Lo : FZ renames XY(1 .. L); XY_Hi : FZ renames XY(L + 1 .. XY'Last); -- A zero-padded double-wide copy of Modulus, to satisfy Ch.5's FZ_Mod M : FZ(XY'Range); begin -- Place the Modulus in a double-width M, as FZ_Mod currently demands M(Modulus'Range) := Modulus; M(L + 1 .. M'Last) := (others => 0); -- XY_Lo:XY_Hi := X * Y FZ_Mul_Egyptian(X, Y, XY_Lo, XY_Hi); -- XY := XY mod M FZ_Mod(XY, M, XY); -- The bottom half of XY is our modular product; top half is always 0 Product := XY_Lo; end FZ_Mod_Mul; pragma Inline_Always(FZ_Mod_Mul); |
This FZ_Mod_Mul multiplies X and Y using the barbaric FZ_Mul_Egyptian algorithm from Chapter 5; then subsequently divides XY -- their product -- by Modulus, and returns the remainder -- using the FZ_Mod from Chapter 5.
Some of the wastefulness of the above FZ_Mod_Mul will immediately stand out to the reader. In subsequent Chapters, we will methodically strip it away. For now, we are concerned strictly with obtaining a minimal and correct baseline against which to work.
Now we can define a modular exponentiation algorithm:
-- Modular Exponent: Result := Base^Exponent mod Modulus procedure FZ_Mod_Exp(Base : in FZ; Exponent : in FZ; Modulus : in FZ; Result : out FZ) is -- Working register for the squaring B : FZ(Base'Range) := Base; -- Register for cycling through the bits of E E : FZ(Exponent'Range) := Exponent; -- Register for the Mux operation T : FZ(Result'Range); begin -- Result := 1 WBool_To_FZ(1, Result); -- For each bit of Result width: for i in 1 .. FZ_Bitness(Result) loop -- T := Result * B mod Modulus FZ_Mod_Mul(X => Result, Y => B, Modulus => Modulus, Product => T); -- Sel is the current low bit of E; -- When Sel=0 -> Result := Result; -- When Sel=1 -> Result := T FZ_Mux(X => Result, Y => T, Result => Result, Sel => FZ_OddP(E)); -- Advance to the next bit of E FZ_ShiftRight(E, E, 1); -- B := B*B mod Modulus FZ_Mod_Mul(X => B, Y => B, Modulus => Modulus, Product => B); end loop; end FZ_Mod_Exp; pragma Inline_Always(FZ_Mod_Exp); |
This is the traditional right-to-left binary method, as seen in e.g. Vol. 2 of D. E. Knuth's AOCP. The only substantial departure from the schoolbook algorithm is the elimination of branching on secret bits. The multiplication step is always carried out, and FZ_Mux is used to either keep, or throw away the answer.
Specifically: Result is initially equal to 1. B initially equals the Base; E -- the Exponent. Now we iterate for a fixed number of cycles, equal to the bitness of Result (which is also equal to the bitness of all three operands.)
In each iteration:
... We multiply Result with the current B, modulo the Modulus, and assign the result to temporary register T.
... And now, if the current bottom bit (determined via FZ_OddP) of E is a zero, we end up discarding (in constant-time) T -- the output of the modular multiplication in the previous step, via FZ_Mux (See Chapter 1). But if this bottom bit is a one, then T is not discarded, and becomes the new value of Result.
... Now E, where we had placed the Exponent at the beginning, is cranked right-wise by one bit (i.e. divided by 2). The next highest bit will now be found at the bottom position, for use in the next iteration.
... Finally, the register B is squared modulo the Modulus.
After the final iteration, Result will contain Base raised to the Exponent power modulo the Modulus.
And that's all for the new unit:
end FZ_ModEx; |
Now let's remember that, as in every other FFA operation, the CPU time consumed by our new modular multiplication and modular exponentiation algorithms is independent of the Hamming weights of the operands. Concretely, e.g., 1 to the 1st power mod 1:
time echo -E ".~.~.~.1.1.1X" | ./bin/ffa_calc 1024 32 |
... will take -- and for any given bitness -- the same, within the margin of error of your Unix time utility, amount of time to compute, as maxint to the maxint-th power modulo maxint:
time echo -E ".1.1.1.~.~.~X" | ./bin/ffa_calc 1024 32 |
Verify this to your satisfaction.
And now, for some empirical data. On a certain 3 GHz Opteron, timed and plotted logarithmically:
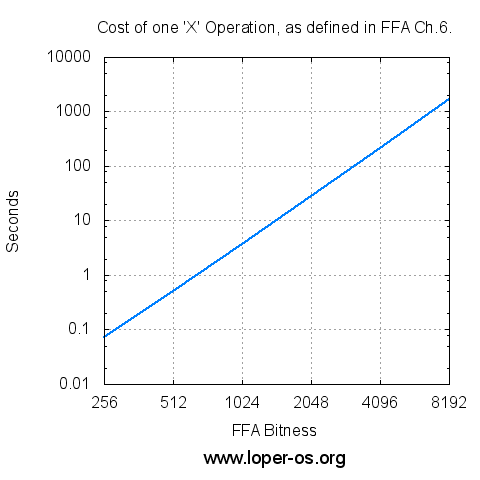
(Click here to see the raw numbers)
Perhaps not quite as "geological" as the reader expected! We can actually fire this primitive RSAtron in anger! Let's verify the RSA seal of ffa_ch6_simplest_rsa.vpatch, the Chapter 6 code itself, using itself:
First, take the seal:
$ pgpdump -i ffa_ch6_simplest_rsa.vpatch.asciilifeform.sig |
... and dump it to a human-readable form:
Old: Signature Packet(tag 2)(284 bytes) Ver 4 - new Sig type - Signature of a binary document(0x00). Pub alg - RSA Encrypt or Sign(pub 1) Hash alg - SHA512(hash 10) Hashed Sub: signature creation time(sub 2)(4 bytes) Time - Sat Jan 6 11:47:07 EST 2018 Sub: issuer key ID(sub 16)(8 bytes) Key ID - 0xB98228A001ABFFC7 Hash left 2 bytes - 62 55 RSA m^d mod n(2047 bits) - 5b 6a 8a 0a cf 4f 4d b3 f8 2e ac 2d 20 25 5e 4d f3 e4 b7 c7 99 60 32 10 76 6f 26 ef 87 c8 98 0e 73 75 79 ec 08 e6 50 5a 51 d1 96 54 c2 6d 80 6b af 1b 62 f9 c0 32 e0 b1 3d 02 af 99 f7 31 3b fc fd 68 da 46 83 6e ca 52 9d 73 60 94 85 50 f9 82 c6 47 6c 05 4a 97 fd 01 63 5a b4 4b fb db e2 a9 0b e0 6f 79 84 ac 85 34 c3 86 13 74 7f 34 0c 18 17 6e 6d 5f 0c 10 24 6a 2f ce 3a 66 8e ac b6 16 5c 20 52 49 7c a2 ee 48 3f 4f d8 d0 6a 99 11 bd 97 e9 b6 72 05 21 d8 72 bd 08 ff 8d a1 1a 1b 8d b1 47 f2 52 e4 e6 9a e6 20 1d 3b 37 4b 17 1d f4 45 ef 2b f5 09 d4 68 fd 57 ce b5 84 03 49 b1 4c 6e 2a aa 19 4d 95 31 d2 38 b8 5b 8f 0d d3 52 d1 e5 96 71 53 9b 42 98 49 e5 d9 65 e4 38 bf 9e ff c3 38 df 9a ad f3 04 c4 13 0d 5a 05 e0 06 ed 85 5f 37 a0 62 42 28 09 7e f9 2f 6e 78 ca e0 cb 97 -> PKCS-1 |
Now, obtain my public modulus:
$ pgpdump -i ~/.wot/asciilifeform.asc |
Old: Public Key Packet(tag 6)(269 bytes) Ver 4 - new Public key creation time - Thu Dec 20 12:49:24 EST 2012 Pub alg - RSA Encrypt or Sign(pub 1) RSA n(2048 bits) - cd d4 9a 67 4b af 76 d3 b7 3e 25 bc 6d f6 6e f3 ab ed dc a4 61 d3 cc b6 41 67 93 e3 43 7c 78 06 56 26 94 73 c2 21 2d 5f d5 ee d1 7a a0 67 fe c0 01 d8 e7 6e c9 01 ed ed f9 60 30 4f 89 1b d3 ca d7 f9 a3 35 d1 a2 ec 37 ea be ff 3f be 6d 3c 72 6d c6 8e 59 9e bf e5 45 6e f1 98 13 39 8c d7 d5 48 d7 46 a3 0a a4 7d 42 93 96 8b fb af cb f6 5a 90 df fc 87 81 6f ee 2a 01 e1 dc 69 9f 4d da bb 84 96 55 14 c0 d9 09 d5 4f da 70 62 a2 03 7b 50 b7 71 c1 53 d5 42 9b a4 ba 33 5e ab 84 0f 95 51 e9 cd 9d f8 bb 4a 6d c3 ed 13 18 ff 39 69 f7 b9 9d 9f b9 0c ab 96 88 13 f8 ad 4f 9a 06 9c 96 39 a7 4d 70 a6 59 c6 9c 29 69 25 67 ce 86 3b 88 e1 91 cc 95 35 b9 1b 41 7d 0a f1 4b e0 9c 78 b5 3a f9 c5 f4 94 bc f2 c6 03 49 ff a9 3c 81 e8 17 ac 68 2f 00 55 a6 07 bb 56 d6 a2 81 c1 a0 4c ef e1 RSA e(17 bits) - 01 00 01 ...~~~crapola snipped~~~... |
But let us now "thank" the malignant idiocy of W. Koch (see also)... Because we will have to patch GPG in order to learn the RFC4880 turd that it uses as "the signature" to compare against when verifying a seal:
diff -uNr a/gnupg-1.4.10/cipher/rsa.c b/gnupg-1.4.10/cipher/rsa.c --- a/gnupg-1.4.10/cipher/rsa.c 2008-12-11 11:40:06.000000000 -0500 +++ b/gnupg-1.4.10/cipher/rsa.c 2018-01-06 15:15:55.000000000 -0500 @@ -444,6 +444,16 @@ result = mpi_alloc ( mpi_nlimb_hint_from_nbits (160) ); public( result, data[0], &pk ); rc = mpi_cmp( result, hash )? G10ERR_BAD_SIGN:0; + + /* Enable dumping of raw sig verification operands: */ + if( DBG_CIPHER ) { + log_mpidump(" data = ", data[0] ); + log_mpidump(" pk.n = ", pk.n ); + log_mpidump(" pk.e = ", pk.e ); + log_mpidump(" hash = ", hash ); + log_mpidump(" result= ", result ); + } + mpi_free(result); return rc; |
So we built it; and now let's run the seal verification with this debuggism:
$ ~/gpg-patched/gnupg-1.4.10/g10/gpg --debug-all --verify ch6.vpatch.sig ch6.vpatch |
And obtain:
(From this point on, lines were wrapped and reindented for clarity:)
...~~~crapola snipped~~~... gpg: data = 5B6A8A0ACF4F4DB3F82EAC2D20255E4DF3E4B7C799603210766F26EF87C8980E737579 EC08E6505A51D19654C26D806BAF1B62F9C032E0B13D02AF99F7313BFCFD68DA46836E CA529D7360948550F982C6476C054A97FD01635AB44BFBDBE2A90BE06F7984AC8534C3 8613747F340C18176E6D5F0C10246A2FCE3A668EACB6165C2052497CA2EE483F4FD8D0 6A9911BD97E9B6720521D872BD08FF8DA11A1B8DB147F252E4E69AE6201D3B374B171D F445EF2BF509D468FD57CEB5840349B14C6E2AAA194D9531D238B85B8F0DD352D1E596 71539B429849E5D965E438BF9EFFC338DF9AADF304C4130D5A05E006ED855F37A06242 28097EF92F6E78CAE0CB97 gpg: pk.n = CDD49A674BAF76D3B73E25BC6DF66EF3ABEDDCA461D3CCB6416793E3437C7806562694 73C2212D5FD5EED17AA067FEC001D8E76EC901EDEDF960304F891BD3CAD7F9A335D1A2 EC37EABEFF3FBE6D3C726DC68E599EBFE5456EF19813398CD7D548D746A30AA47D4293 968BFBAFCBF65A90DFFC87816FEE2A01E1DC699F4DDABB84965514C0D909D54FDA7062 A2037B50B771C153D5429BA4BA335EAB840F9551E9CD9DF8BB4A6DC3ED1318FF3969F7 B99D9FB90CAB968813F8AD4F9A069C9639A74D70A659C69C29692567CE863B88E191CC 9535B91B417D0AF14BE09C78B53AF9C5F494BCF2C60349FFA93C81E817AC682F0055A6 07BB56D6A281C1A04CEFE1 gpg: pk.e = 10001 gpg: hash = 1FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF003051300 D0609608648016503040203050004406255509399A3AF322C486C770C5F7F6E05E18FC 3E2219A03CA56C7501426A597187468B2F71B4A198C807171B73D0E7DBC3EEF6EA6AFF 693DE58E18FF84395BE gpg: result= 1FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF003051300 D0609608648016503040203050004406255509399A3AF322C486C770C5F7F6E05E18FC 3E2219A03CA56C7501426A597187468B2F71B4A198C807171B73D0E7DBC3EEF6EA6AFF 693DE58E18FF84395BE ...~~~crapola snipped~~~... |
And finally, let's turn this into a FFACalc tape:
( the seal of ffa_ch6_simplest_rsa.vpatch.asciilifeform.sig : ) . 5B6A8A0ACF4F4DB3F82EAC2D20255E4DF3E4B7C799603210766F26EF87C8980E737579 EC08E6505A51D19654C26D806BAF1B62F9C032E0B13D02AF99F7313BFCFD68DA46836E CA529D7360948550F982C6476C054A97FD01635AB44BFBDBE2A90BE06F7984AC8534C3 8613747F340C18176E6D5F0C10246A2FCE3A668EACB6165C2052497CA2EE483F4FD8D0 6A9911BD97E9B6720521D872BD08FF8DA11A1B8DB147F252E4E69AE6201D3B374B171D F445EF2BF509D468FD57CEB5840349B14C6E2AAA194D9531D238B85B8F0DD352D1E596 71539B429849E5D965E438BF9EFFC338DF9AADF304C4130D5A05E006ED855F37A06242 28097EF92F6E78CAE0CB97 ( my public rsa exponent : ) . 10001 ( my public rsa modulus : ) . CDD49A674BAF76D3B73E25BC6DF66EF3ABEDDCA461D3CCB6416793E3437C7806562694 73C2212D5FD5EED17AA067FEC001D8E76EC901EDEDF960304F891BD3CAD7F9A335D1A2 EC37EABEFF3FBE6D3C726DC68E599EBFE5456EF19813398CD7D548D746A30AA47D4293 968BFBAFCBF65A90DFFC87816FEE2A01E1DC699F4DDABB84965514C0D909D54FDA7062 A2037B50B771C153D5429BA4BA335EAB840F9551E9CD9DF8BB4A6DC3ED1318FF3969F7 B99D9FB90CAB968813F8AD4F9A069C9639A74D70A659C69C29692567CE863B88E191CC 9535B91B417D0AF14BE09C78B53AF9C5F494BCF2C60349FFA93C81E817AC682F0055A6 07BB56D6A281C1A04CEFE1 ( now modularly-exponentiate it : ) X ( ... and print the output .) # |
... and play the tape! :
$ time cat ch6_rsa_tape.txt | ./bin/ffa_calc 2048 32 |
... and unsurprisingly:
0001FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF003051 300D0609608648016503040203050004406255509399A3AF322C486C770C5F7F6E05E1 8FC3E2219A03CA56C7501426A597187468B2F71B4A198C807171B73D0E7DBC3EEF6EA6 AFF693DE58E18FF84395BE real 0m27.956s user 0m27.927s sys 0m0.003s |
Guess what? The correct answer. Took an entire half-minute, however, to complete on this (same as where the log plot was made) machine.
In the next Chapter, we will investigate some elementary improvements in efficiency!
~To be continued!~


A general question.
IMO bitcoin script turned out to be a mistake; it was supposed to add extensibility but in practice all interesting opcodes were hastily disabled so that only a few (perharps one) script forms are useful. Relying on scripts (instead of having a concept of accounts) leads to pointless complexity (needs signatures for every input, even if under the same key, weird hashing ...)
You mentioned that you intend to use something like FFACalc code ('P' or whatever) for public keys. Is it still the plan? IMO would be a mistake, for the same reasons. Either everything but keys is standardized (and then no point in P code in pubkeys, only a new sig/encrypt format is needed) or every key will need to carry a 10k (or more) keccak implementation (for padding...)
Dear apeloyee,
Bitcoin's Forthlike opcodes were disabled because its Microshit-besotted halfwit author left trivially-exploitable bugs in his implementation. (Rather than "because too complicated.")
And yes, Pcode is still the plan. Because if I want my public key to consist of three different RSA moduli which I generated on three different boxes using three different methods, and all signatures internally consist of three bitstrings, one RSA-signed per respective modulus (and, naturally, all three must match for a "true" output of a verification run) -- I should be able to do this.
Or if I want my key to consist of RSA and Cramer-Shoup running in tandem on Shamir-splits - I should also be able to do this.
Or any other number-theoretical cipher, or combination thereof.
Unnecessary standardization is poison.
As for hashing, there will not, per the current plan, be a Keccak either hardwired internally inside P or hacked together in anybody's Pcode -- the operator is responsible for padding and otherwise preprocessing his payloads as he sees fit, using external tools. P carries out solely arithmetic and simple bitwise manipulations.
Edit:See also this thread.
Edit #2:...and also this one.
Yours,
-S
So 'P' is not a self-contained tool for sig verification. That's ok, but verifying padding on an RSA signature is not optional, and not just any padding will do. (Otherwise it's possible to do existential forgery; it won't fool a human, but can trick a machine into letting "signed" crapflood in)... Unlike sha512 etc. I don't know of a widespread standalone tool to verify padding, moverover, it is dependent on key size and, thus, padding verification really should be part of a public key.
What to do?
Dear apeloyee,
I don't see the problem -- output of 'P' gets piped to, e.g., Diana Coman's (or PeterL's) ada-keccak util. Or another dedicated proggy. The latter outputs "pass"/"fail".
Alternatively can come up with a purely number-theoretical padding algorithm. Which in fact would be The Right Thing, as hashes are unfounded voodoo ( for the same reason that symmetric ciphers are.)
Edit: It isn't even clear to me why the usual type of "padding" ( for preventing existential forgery ) would even be necessary in a multi-modulus ( or even multi-asymm-cipher ) scheme, as described in the earlier comment. Good luck coming up with an existential forgery that satisfies all N prongs of the fork, even if the recombination algo for the prongs is a simple one (e.g. Reed-Solomon)
Edit #2:See also today's thread re methods of "padding" without traditional hashes.
Yours,
-S